By Thomas Konings
One of the most thrilling developments in Machine Learning is that of self-driving cars. Companies such as GM, Google and Tesla have been making huge advancements in creating a completely autonomous vehicle. Here at InfoFarm, we take on the challenge to join in on the action.
Motivated by PXL Digitals’s upcoming Race To The Future, we are developing an AI-powered MCU car that will compete on the 2nd of October on their first edition. During my one-month employment as a student intern at InfoFarm, I was given the opportunity to contribute to this awesome project.
Setting the scene….no, the road!
On October 2nd, 2020, PXL Digital and Corda Campus will organize the first edition of the Race To The Future in which several teams will compete against each other with their AI-powered MCU cars. Each team will get 3 chances to set the fastest lap time and win the prestigious award of …. well, bragging rights of course!
Unlike in Formula1, where you have both a constructor and driver championship, this competition revolves around having no driver at all. Supplied by PXL with a starter pack on hardware and software, each team has to use artificial intelligence to teach the MCU car how to drive by itself. The 300m racetrack will be limited on both sides by red, thick tubes that will have to help the AI make the right decision on where to steer to and how much throttle to supply.
During my one-month employment as a student intern at InfoFarm, I helped lay the groundwork for this challenging project. In this blogpost, I’ll take you through the basic ideas we applied that will serve as stepping-stones for further development in preparation for this Race To The Future.
So, continue reading to find out if our AI will be able to safely drive around the track or if we should consider getting a full omnium insurance for our MCU car 😉
The Neural Network architecture
When racing, the AI is fed with an image of the track ahead and should predict the adjustment needed to the trajectory of the car in order to stay in between the track limits (the red tubes). These adjustments consist of an angle and throttle correction that are both mapped between –1 and 1, corresponding to left/right and forward/backward respectively.
The essence of this AI is that it should recognize patterns (track limits) on an image. For this reason, a Convolutional Neural Network or CNN is chosen as the basis for our neural network architecture. Following this research of the NVIDIA Corporation, we use the architecture pictured below as the network that transforms the input image of dimensions 120x160x3 to a flat 1×50 vector through multiple colvolutional and fully-connected layers. From there on, we can choose different approaches to transform this 1×50 vector to the desired output of two final floats.
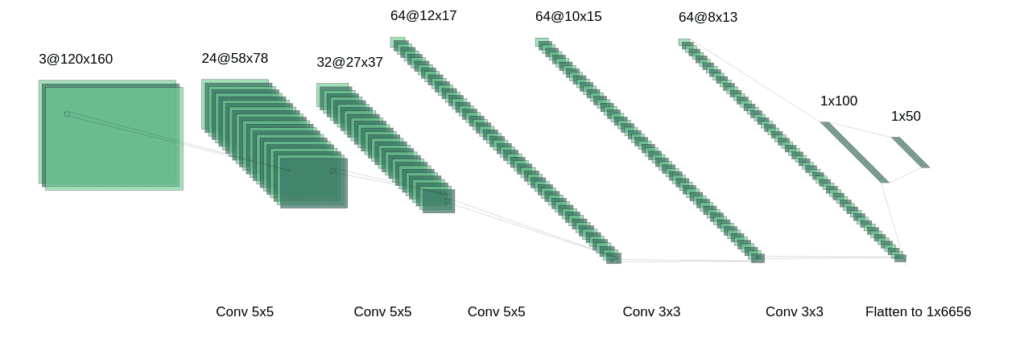
Without going into too much detail, we can transform the 1×50 to an output angle and throttle in 3 ways:
- The Linear Case: We choose to add two fully connected layers that produce two floats separately.
- The Categorical Case: Through two fully connected layers, we produce 2 probability distributions for which we choose the output with the highest probability.
- The Recurrent Case: We opt for the Linear model in combination with a second input: the angle and throttle of the previous iteration. The output predicted by the Linear model is correlated with the output of the model from the previous frame. In this way, the prediction becomes more robust against sudden big changes in angle or throttle that can occur from irregularities in the input image.
For now, we will only show results of the Linear and Categorical case.
The Grand Prix of InfoFarm
The key to any successful neural network is… (You’ve guessed it already) … training data! Unfortunately, we were not (yet) able to recreate the exact racetrack conditions, but with the help of a little imagination, we could collect about 8GB on data already from a track that we nicknamed the “Grand Prix of InfoFarm”. After carefully pre-processing the created data, we had a solid 6GB to get started with.
To get the most out of a dataset, it is often augmented by applying different transformations. Below, you can see an animation of a couple of augmentations we use.
The Sun can potentially confuse our CNN by introducing shadows to our image and a varying brightness. To arm our network against these irregularities, we start from the original image and apply a random shadow and brightness (ShBr) augmentation (upper left) which changes for every frame.
Next, we do not wish to train our network on one specific track colour, nor to focus on unimportant sharp features such as grass, tile joints, stones and others. Therefore, we grayscale and blur the image (upper right).
Since the track limits are and will be distinct features in the image, we can use the Canny Edge Detection operator (lower left) to detect the track limits.
Finally, it is obvious that the region of interest is located in the lower 60-70% of the image. Using a mask on the upper pixels, we ignore any background features.
The Grand Prix of InfoFarm
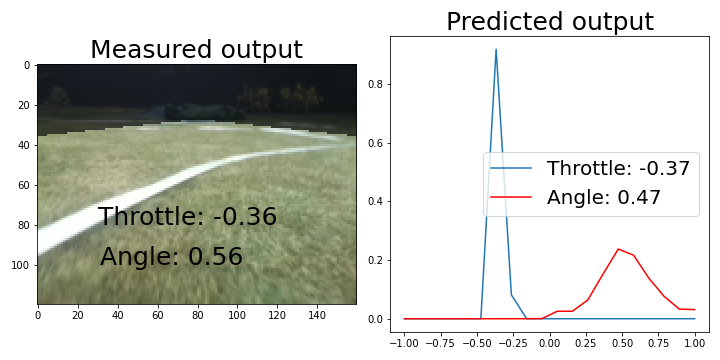
With our implementation of the Gradient-weighted Class Activation Map (or grad-CAM) algorithm, we can visualize the last convolutional layer of the neural network as it processes a new image. For a Linear model, trained with a shadow and brightness variations, this gives the following result as it decides the angle output (see figure below).
The left hand side shows the original image with the recorded throttle and angle during training. The right hand side shows the grad-CAM output together with the predicted angle and throttle. It is nice to see that the angle is fairly well reproduced and that the network shows activity close to the track limits when passing close to them.
It should be clear by now that the angle is the most important output parameter to guarantee a successful race. It is also the most difficult one to predict. This is clear from the plot below, where the right hand side shows the distribution of probabilities for a Masked Categorical model, because the uncertainty (width of the distribution) is far greater for the angle than for the throttle.
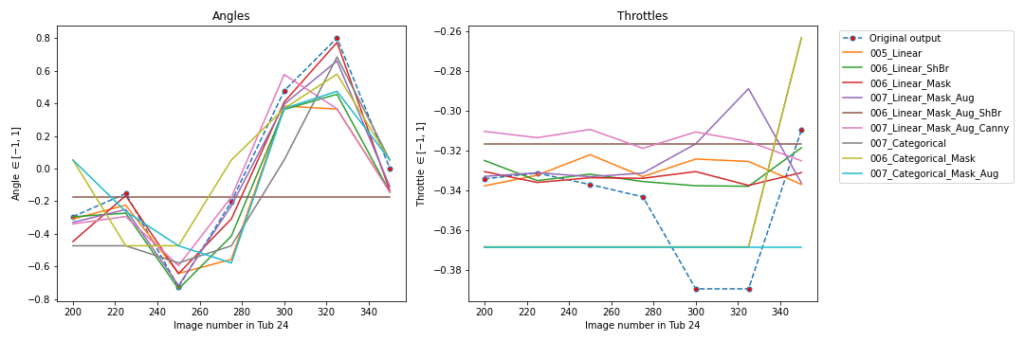
Finally, we can compare a large amount of models to see if there are any significant discrepancies between them. Below, we used 9 different models to evaluate a range of images and predict the angle (left plot) and the throttle (right plot).
There is no large variation in the prediction of throttles. Why? The training data did not show large fluctuations and as a result, so doesn’t the model.
The Categorical models discretize a continuous range from -1 to 1 into 20 chunks of equal size so that the resolution is about 0.1. Since the scale of the y-axis is around the same number, the Categorical models will not be able to predict small fluctuations in the throttle. (It doesn’t really matter if you predict -0.3 or -0.4, as long as we do not go backwards…)
The predictions for the angles all follow the same trend but show some more deviation from the original output. Overall, we can be pretty satisfied with the current performance of our networks!
The road ahead…
So what do you think?… Pretty cool right?
There is much more to do building up to October 2nd and many more interesting questions to answer. How will the current models react to different track conditions (e.g. red tubes)? Will the Recurrent approach give us any advantage? And perhaps most importantly, will we need that full omnium insurance for our MCU car or will our neural network handle the car smoothly?
I am very excited to see how my talented colleagues will continue to work on this project and I will be tuning in to hear all the interesting new improvements they make.
Finally, a big thanks to Lorentz Feyen and Ben Vermeersch for giving me, a machine learning rookie, the opportunity to contribute to this challenging project and for supervising me throughout this month.